여기에서 모델명을 참조하십시오.
파이토치 버전 1.8.0입니다.
SASE 모델은 크게 다음과 같이 분류됩니다.
- 임베더
- 자기 인식
- 분류기
- 손실 함수
라이브러리에 들어가기 전에 먼저 라이브러리를 가져와야 합니다.
import torch
import torch.nn as nn
import torch.nn.functional as F1. 임베더
임베더는 말 그대로 원어를 임베딩하고 Bi-LSTM을 통해 컨텍스트 정보를 압축하는 부분이다.
word2vec을 따로 학습시켰습니다. 다음과 같이 구현했습니다.
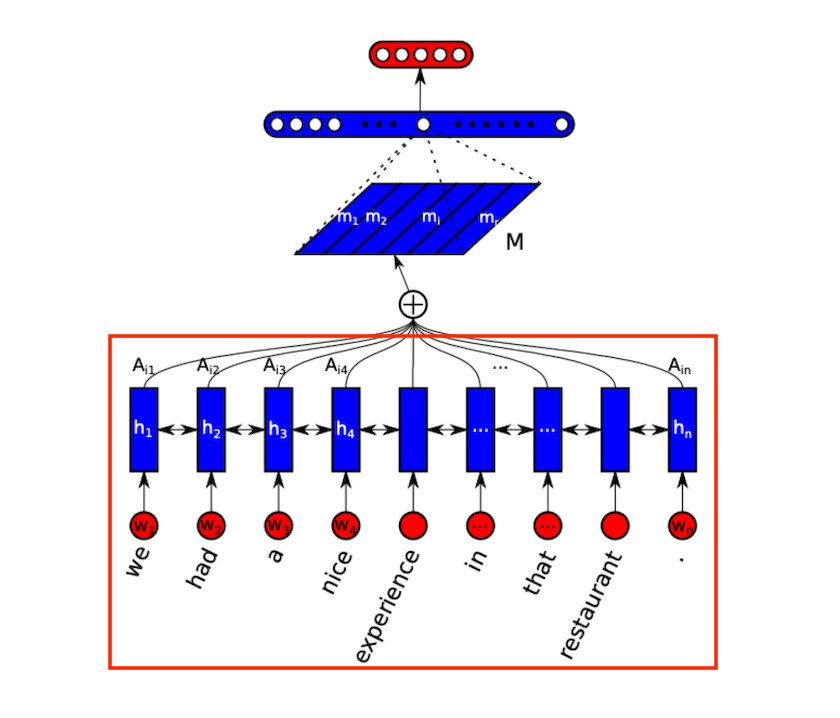
모델 이미지를 보면 위의 빨간 사각형 박스라고 생각하시면 됩니다.
수식을 살펴보겠습니다.
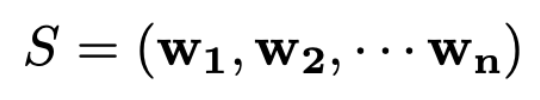
상단 부분은 word2vec embed를 불러오는 부분이라고 생각하시면 됩니다.
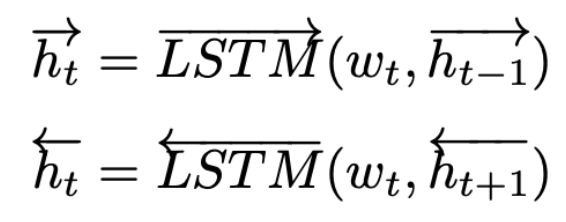
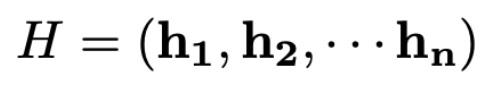
위 수식은 bi-LSTM을 통해 나온 부분이라고 생각하시면 됩니다.
class SentenceEmbedder(nn.Module):
def __init__(self, cfg, embeddings=None, vocab_size=None):
super(SentenceEmbedder, self).__init__()
self.hidden_layer = cfg('hidden_layer')
self.att_hidden_layer = cfg('att_hidden_layer')
self.gaussian = GaussianNoise(cfg('gaussian'))
self.dropout = nn.Dropout(p=cfg('dropout'))
## 임베딩 불러오기
if embeddings is not None:
self.embedding_dim = cfg('embed_dim_word')
self.embedding = nn.Embedding.from_pretrained(embeddings=embeddings,
freeze=True)
else:
self.embedding_dim = cfg('embed_dim_word')
self.embedding = nn.Embedding(num_embeddings=vocab_size,
embedding_dim=self.embedding_dim)
## LSTM 선언
self.lstm = nn.LSTM(input_size=self.embedding_dim, hidden_size=self.hidden_layer, num_layers=2, batch_first=True, bidirectional=True)
def forward(self, input):
S = self.embedding(input)
S = self.gaussian(S)
S = self.dropout(S)
H, _ = self.lstm(S)
return H여기서는 가우시안 노이즈를 사용했습니다. 필요하시면 저처럼 쓰시면 됩니다.
class GaussianNoise(nn.Module):
def __init__(self, std):
super().__init__()
self.std = std
def forward(self, x):
if self.training:
noise = torch.randn_like(x) * self.std
return x + noise
return x2. 자기 인식
이번에는 자기 인식을 하는 부분입니다.
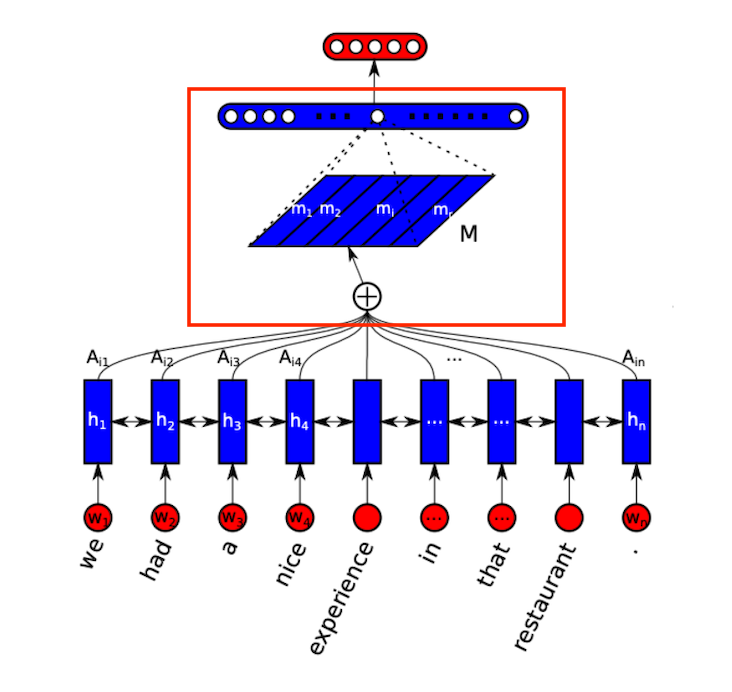
그림에서 위의 빨간색 부분에 해당합니다.
결과 벡터로 방문 벡터인 M을 생성하는 부분입니다.
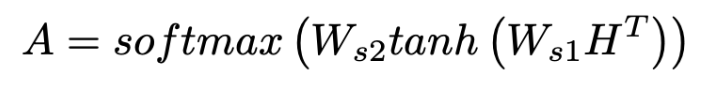
먼저 주목 가치를 얻습니다.
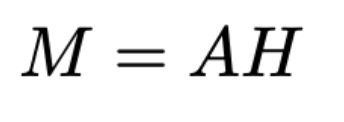
그런 다음 원래 벡터를 곱하여 유지된 벡터를 완성합니다.
class SelfAttention(nn.Module):
def __init__(self, cfg):
super(SelfAttention, self).__init__()
self.hidden_layer = cfg('hidden_layer')
self.att_hidden_layer = cfg('att_hidden_layer')
self.hops = hops
## 어텐션 구하는 부분
self.att_score = nn.Sequential(
nn.Linear(self.hidden_layer*2, self.att_hidden_layer),
nn.Tanh(),
nn.Linear(self.att_hidden_layer, self.hops)
)
def forward(self,H):
A = self.att_score(H)
A = nn.functional.softmax(A, dim=1)
A = weights.transpose(1, 2)
M = torch.bmm(A, H)
return M, A3. 분류기 및 손실 기능
드디어 마지막 부분.
여기에 손실함수를 붙인 이유는 프로베니우스 노름의 계산이 클래스 내부에서 이루어지기 때문이다.
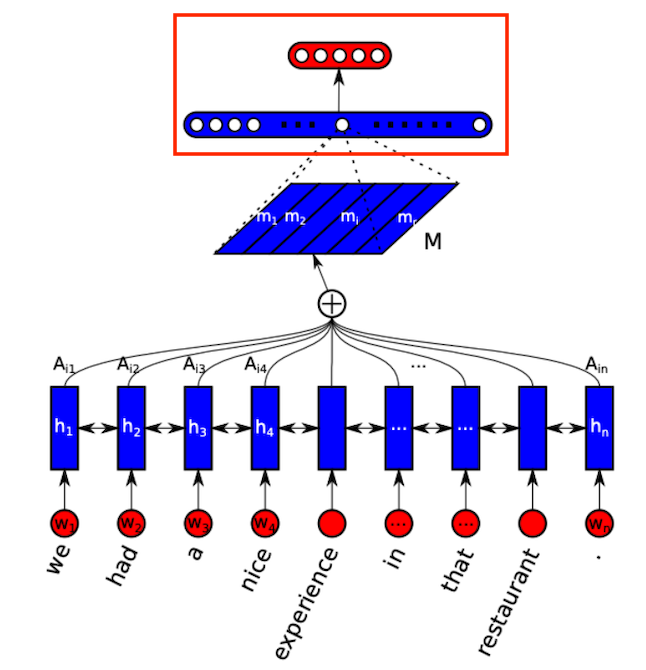
위의 red box 부분과 loss 부분을 함께 구현해보자.
분류자 부분은 fc 레이어를 통과하기만 하면 됩니다.
살펴봐야 할 부분은 손실 함수 부분입니다.
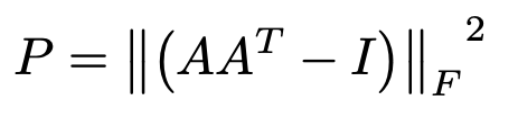
위와 같이 수식을 작성해주세요.
class SelfAttentiveModel(nn.Module):
def __init__(self, cfg, embeddings=None, char_vocab=None, vocab_size=None):
super(SelfAttentiveModel, self).__init__()
## parameter setting
self.hidden_layer = cfg('hidden_layer')
self.att_hidden_layer = cfg('att_hidden_layer')
self.classifier_hidden_layer = cfg('classifier_hidden_layer')
self.hops = cfg('hops')
self.dropout_f = nn.Dropout(p=cfg('dropout_dens'))
## embedder define
self.embedder = SentenceEmbedder(cfg, embeddings=embeddings)
## attention define
self.attention = SelfAttention(cfg)
## final layer
self.fc = nn.Sequential(
nn.Linear(self.hops*self.hidden_layer*4, self.classifier_hidden_layer),
nn.ReLU(),
nn.Linear(self.classifier_hidden_layer, cfg('target_num'))
)
def _frobenius(self, attention):
batch_size = attention.shape(0)
AAT = torch.bmm(attention, attention.transpose(1,2))
I = torch.eye(self.hops).unsqueeze(0).repeat(batch_size, 1, 1).cuda()
penalization_term = torch.norm(AAT - I) / batch_size
return penalization_term
def forward(self, input):
## embedding
H = self.embedding(input)
M, A = self.attention(H)
M = M.view(-1,self.hops*self.hidden_layer*2)
final = self.fc(M)
loss = self._frobenius(A)
return final, loss모델에서 계산한 손실에 위의 손실을 더하면 됩니다.