통계적 추론을 입력하기 전에 수리 통계의 내용 주문 통계이 중요한 사항을 확인하십시오
먼저 이해하기 위해 예를 연구하십시오.
예1)

1 단계) Y1의 누적 분포 함수(cdf) 찾기 Fy1(y) = P(Y1<=y)
P(Y1<=y) = 1 - P(Y1>y) : cdf 속성
= 1 – P(X1>y, X2>y): X1과 X2의 최소값이 y보다 크면 X1과 X2 모두 y보다 큽니다.
= 1 – P(X1>y) * P(X2>y) : 랜덤 변수(rv)는 서로 독립적이기 때문에
= 1 – (P(X1>y))^2 : 두 확률 변수가 동일한 확률 분포를 따르기 때문에
= 1 – (1 – Fx1(y))^2
마지막으로 Y1의 cdf는 분포가 이미 알려진 X1의 cdf로 구했습니다.
2 단계) Y1의 확률 밀도 함수 결정(pdf) fY1(y)
pdf는 위의 cdf를 y에 대해 미분하여 얻을 수 있습니다.
fy1(y) = d/dy Fy1)(y)
= 2fx1(y)(1-fx1(y))
그런 다음 위의 예에서 랜덤 변수 Y2 = max(X1,X2)에 대해 cdf 및 pdf를 검색합니다.
1 단계) Y2의 cdf 구하기 Fy2(y) = P(Y2<=y)
= P(X1<=y, X2<=y)
= P(X1<=y)P(X2<=y) 두 개의 독립 확률 변수가 함께 발생할 확률은 단순히 각각의 확률을 곱한 것입니다.
= (P(X1<=y))^2 : 확률분포가 같기 때문에
= (Fx1(y))^2
유사하게 Y2의 cdf는 분포가 이미 알려진 X1의 cdf로 구했습니다.
2 단계) Y2의 pdf fy2(y) 찾기
= d/dy fy2(y)
= 2fx1(y)Fx1(y)
앞의 예가 확률변수가 2개인 경우라면 확률변수가 3개인 경우를 살펴보자.
예2)

Y1, Y2, Y3는 X1, X2, X3을 크기별로 정렬한 순서통계량이라고 할 수 있다.
예: Y1 = 최소(X1, X2, X3), Y2 = 중앙값(X1, X2, X3), Y3 = 최대(X1, X2, X3).
(랜덤 변수의 개수가 계속 늘어나면서 위와 같이 단순히 min, median, max로 표현할 수 없음을 알 수 있습니다.)
먼저 Y1과 Y3의 cdf와 pdf를 모두 찾아봅시다.
이번에는 단계를 나누지 않고 직접 미분하여 PDF를 얻습니다.
1 단계) Fy1(y) = P(Y1<=y)
= 1 – P(Y1>y)
= 1 – P(X1>y)P(X2>y)P(X3>y) : y보다 큰 최소값은 y보다 큰 모든 것과 동일 + 각 무작위 변수는 독립적입니다.
= 1 – (1-(Fx1(y))^3
*일/일 = fy1(y) = 3fx1(y)((1-(Fx1(y))))^2
2 단계) Fy3(y) = P(Y3<=y)
= (P(X1<=y))^3 : 반복 과정을 생략하면 각 랜덤 변수는 독립적이며 최대 값은 y보다 작다는 것은 모두 y보다 작다는 것을 의미합니다.
= (Fx1(y))^3
*일/일 = fy1(y) = 3fx1(y)(fx1(y))^2
마지막으로 Y2의 cdf와 pdf를 찾아보자.
1 단계) Fy2(y) = P(Y2<=y)
이것은 X1, X2 및 X3 중 적어도 두 개가 y보다 작을 확률과 같습니다.
P(Y2<=y) = P(X1<=y, X2<=y, X3<=y): 모든 X가 y보다 작을 때
+ P(X1<=y, X2<=Y, X3>y) : X1, X2가 y보다 작지만 X3이 y보다 클 때
+ P(X1<=y, X2>y, X3<=y) : X1, X3이 y보다 작지만 X2가 y보다 클 때
+P(X1>y, X2<=y, X3<=y) : X2, X3이 y보다 작지만 X1이 y보다 클 때
그러나 각각의 확률변수는 동일한 확률분포를 따르므로,
하단의 세 확률이 같은 것을 확인할 수 있습니다.
따라서 다음과 같이 정리할 수 있습니다.
Fy2(y) =3 * (Fx1(y))^2 * (1-Fx1(y)) + (Fx1(y))^3
*일/일 = fy2(y) = 6 * fx1(y) * fx1(y) * (1-Fx1(y))
이제 pdf와 결합 확률 밀도 함수 결합 pdf를 얻기 위해 이 순서 통계를 일반화하는 공식이 있습니다.
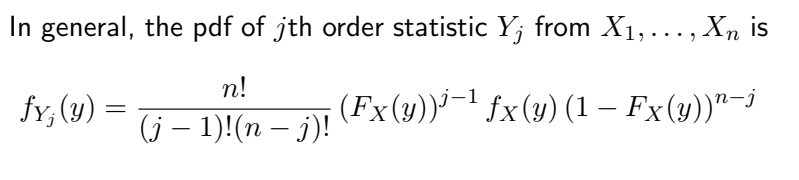
이 공식을 엄밀하게 설명하기 전에 대략적인 이해를 위해 휴리스틱 파생을 만들어 봅시다.
(이 부분은 자세히 설명할 필요가 없습니다. 교수님께서 통계적 추론을 위한 도구라고 하셨지만,
단, 원리를 이해해야 함)
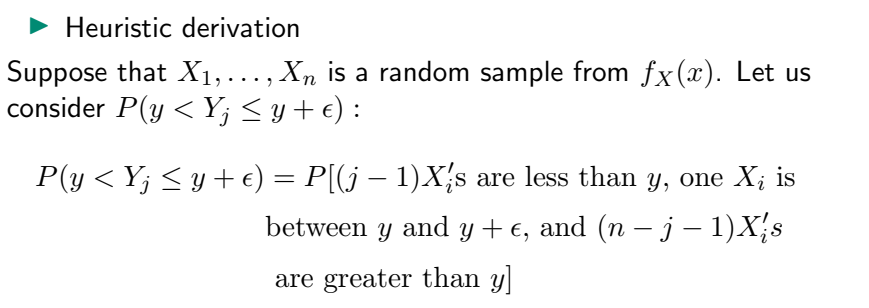
n개의 무작위 변수 X1,…,Xn을 순차적으로 나열하여 구성
Y1,…,Yn 중 j번째 위치에 있는 Yj의 확률입니다.
P(y< Yj <= y+이자형 ) ( 이자형 모든 양수는 0보다 약간 크며 Yj=y+이자형 표현하지 않는 이유는 연속 확률변수에서 P(Y=y)가 항상 0이기 때문이다.)
이해할 수 있습니다.
j번째 선택시
(j-1) Xi는 y보다 작고, Xi는 y와 y+이자형 사이, (nj-1) Xi가 y보다 큽니다.
그러면 위의 예 eg2의 Y2 상황에서와 같이
각 임의 변수 X1,…,Xn에서 어떤 임의 변수가 어떤 간격에 속하는지 결정해야 합니다.
이것은 매우 시간이 많이 걸립니다
이 경우 다항 분포를 사용할 수 있습니다.

x1: Xi가 y보다 작은 경우
x2: Xi가 y보다 크고 y+ε보다 작거나 같은 경우
x3: Xi가 y+ε보다 크면
p1: Xi가 y보다 작을 확률: Fx(y)
p2: Xi가 y보다 크고 y+ε보다 작거나 같을 확률 : Fx(y+이자형 ) – FX(y) (누적 분포 함수의 성질)
p3 Xi가 y+ε보다 클 확률 : 1-Fx(y+이자형 )
x1 = j – 1, x2 = 1, x3 = nj – 1 이고 그대로 대입하여 계산하면 위 식을 유도할 수 있다.
(다음은 미적분학의 내용일 뿐, 기타 통계적 개념은 필요하지 않으므로 생략한다.)
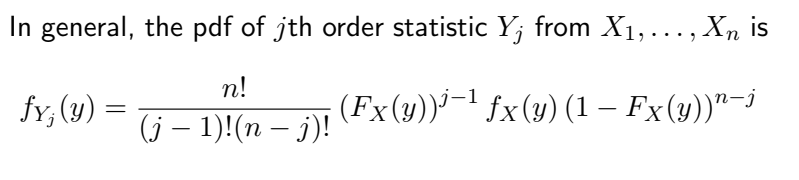
이 공식은 나중에 수정되었습니다.
결합 확률 밀도 함수(결합 pdf)로 확장할 수 있습니다.
i번째 yi 및 j번째 yj가 선택된 경우
x1: Xi가 yi보다 작은 경우
x2: 만약에
x3 : yi+ε이면
x4 : yj인 경우
x5: yj+ε이면
등으로 확장하고 다항 분포로 다시 계산하면 다음 공식을 도출할 수 있습니다.
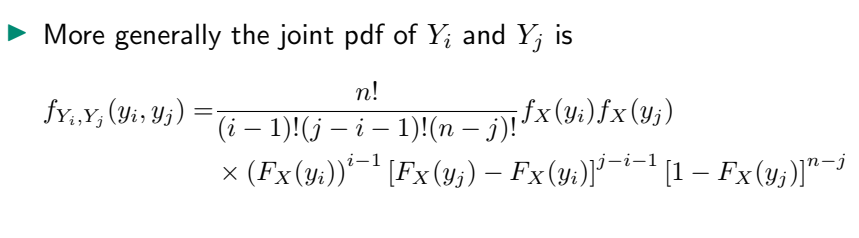
이상으로 향후 통계적 추론 학습에 필요한 자료를 준비했습니다.